SMART Guidelines Starter Kit
2.1.0 - ci-build
![]()
SMART Guidelines Starter Kit
2.1.0 - ci-build
![]()
SMART Guidelines Starter Kit, published by WHO. This guide is not an authorized publication; it is the continuous build for version 2.1.0 built by the FHIR (HL7® FHIR® Standard) CI Build. This version is based on the current content of https://github.com/WorldHealthOrganization/smart-ig-starter-kit/tree/main and changes regularly. See the Directory of published versions
This specification utilizes a subset of ArchiMate notation to visually represent and structure the authoring processes. This distinguishes between the functional description (application layer) and the physical artifacts (technology layer).
This specification uses:
Application Layer: Offers a functional description, typically illustrating processes, functions, and services. This is represented by blue elements.
Technology Layer: Represents actual artifacts, like files, resource instances, or other data objects. This is represented by green elements.
The relations are represented by arrows
Aggregation: Illustrates that an object groups several other objects.
Composition: Indicates that an object is composed of one or more other objects, implying a stronger, "whole-part" relationship compared to aggregation.
Access (Read/Write): Indicates that a process has an artifact as input, or as output.
Related To: A generic relationship with a label specifying the nature of the connection.
Flows to: A relationship where an activity (process) is followed by another activity
The diagram below represents the process for creating an indicator:
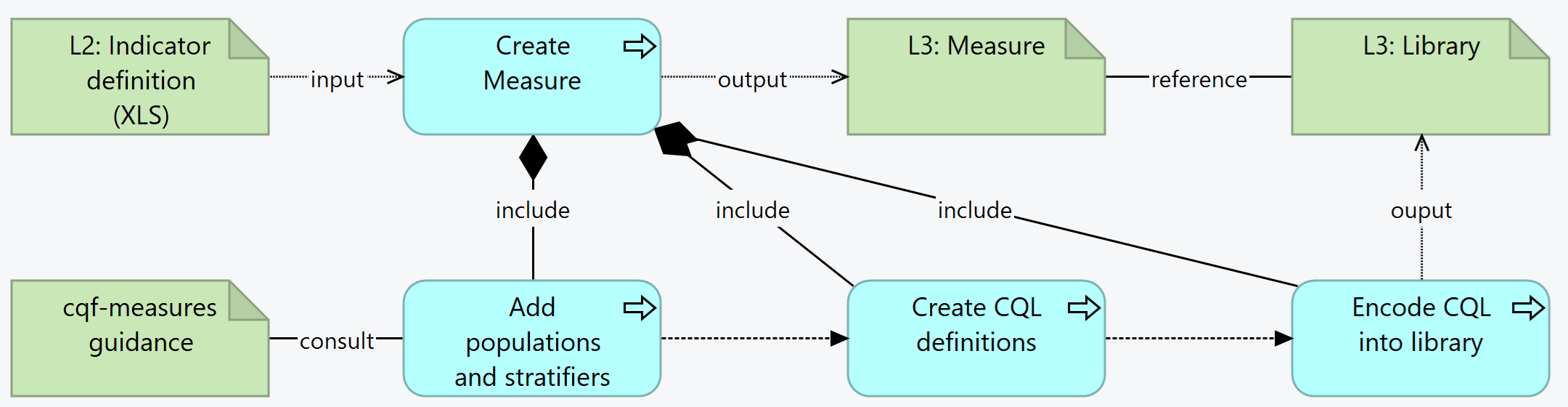
The diagrams capture the essence of transforming an L2 input into the corresponding L3 artifacts through processes. These processes can use different tooling or technologies; however the criteria for output and for process are defined.
To describe the content L3 authors are supposed to produce, the key content of the output artifacts is modeled with PlantUML diagrams. This diagram summarizes the data that is part of an object definition. For example, the diagram below shows that for a ValueSet, the L3 author is required to have a status, a name, an identifier and a URL.